Aujourd’hui, 8 octobre, c’est l’anniversaire de Haruhi Suzumiya, un personnage de manga à l’origine d’une des plus grandes franchises de ces dix dernières années.

Si vous n’avez jamais regardé, je vous conseille vivement de le faire. Mais je vais vous raconter comment j’ai été entraîné par ce soft power japonais (pas si soft, en fait).
2008
C’était il y a 8 ans. En juillet 2008.
À Japan Expo, je croise une fille déguisée en un personnage de manga dont je ne me rappelais plus le nom (Haruhi Suzumiya).
— Il est super ton cosplay ! Je peux te prendre en photo ?
— Ah oui ! Attends un peu… (Elle s’en va.)
Elle va chercher sa copine, et là, elles prennent cette pose :

J’étais légèrement surpris et intrigué, du coup en rentrant je me suis dépêché de mettre les yeux sur les épisodes de La Mélancolie de Haruhi Suzumiya.
Après avoir vu l’épisode 1, je n’ai pas compris. Ça semblait être un film dans le film, avec un humour absurde.
En fait, c’est parce que les épisodes de la série ne sont pas dans l’ordre chronologique. Le premier qu’on regarde est en fait le onzième et ainsi de suite, en tout :
XI I II VII III IX VIII X XIV IV XIII XII V VI.
La plus longue sous-suite croissante est I II III IV V VI, le fil principal de l’intrigue. Imaginez donc la surprise quand, après avoir vu l’épisode II, on tombe sur le VII, qu’on ne comprendra qu’après avoir vu le VI, qui arrive à la toute fin de la saison. Il est d’ailleurs amusant de revoir la série et de repérer tous les détails d’apparence anodins mais qui en fait sont des clins d’œil à la fin de la série. En ce qui me concerne, je suis fan du concept.
En outre, la série fait référence à de nombreux concepts développés dans plusieurs œuvres de science-fiction, ou bien des concepts philosophiques tels que :
- l’hypothèse des cinq minutes de Bertrand Russell ;
- le principe anthropique ;
- quelques éléments que l’on retrouve dans l’univers Marvel ;
- quelques éléments que l’on retrouve dans la série Doctor Who.
C’est un peu de la science-fiction pour enfants, et l’intrigue est super bien ficelée. (Je continue à penser que le pitch est le meilleur pitch possible pour une histoire.) Ça s’inspire en partie de L’Oiseau bleu de Maeterlinck, qui est une autre illustration de la citation de Robert Louis Stevenson : « I travel not to go anywhere, but to go. I travel for travel’s sake. The great affair is to move. »
D’ailleurs, une citation de l’héroïne :
Il ne t’arrivera rien d’amusant si tu ne restes à rien faire.
C’était un truc tout bête, comme ça. Mais à l’époque ça m’a rendu fou. C’est sûrement en partie responsable de la quantité déraisonnable de projets divers que je me suis efforcé d’accomplir ces dernières années.
Fraîchement entré dans ma nouvelle école, j’ai tenté de contaminer un maximum de gens à regarder la série. Une méthode qui marchait bien :
— Non mais regarde JUSTE 3 épisodes ce soir !
— OK.
(Le lendemain.)
— Je te DÉTESTE j’ai dû FINIR LA SÉRIE je me suis couché à MINUIT [etc.]
— De rien.
J’ai rejoint le forum suzumiya.haruhi.fr, qui deviendra une association : la Brigade SOS Francophone1.
2009
Un jour, sur le forum de la Brigade, on apprend qu’une rediffusion est programmée, au Japon, dans l’ordre chronologique.
Certains prophètes du forum, qui ont lu les romans sur lesquels est basée la série, présagent qu’il y aura peut-être une saison 2 basée sur des morceaux d’autres romans, intercalée dans la rediffusion de la saison 1.
Je ne sais pas comment les prophètes ont fait, mais effectivement, le 22 avril 2009, au lieu de suivre le fil de la saison 1, un épisode inédit a été projeté. Et là, je ne vais pas faire un dessin parce que ça commence à devenir compliqué.
C’est ainsi que pendant la diffusion, à raison d’un épisode par semaine2, les prophètes se sont amusés à prédire de quel roman proviendrait l’épisode suivant3.
Dans mon école, on a créé un club anime, pour faire découvrir des séries animées japonaises, notamment celle-ci. À l’époque, l’école était suffisamment cool pour qu’on puisse demander :
— Je peux avoir l’amphi B s’il vous plaît ?
— C’est pour quoi faire ?
— Projeter des séries animées japonaises.
— OK.
(Ça marchait aussi pour les anniversaires.) On a donc placardé cette affiche partout :

Quelques réactions :
— Mais vous êtes débiles ! Les gens vont rien comprendre.
— C’est le but.
Et on a quand même rempli l’amphi.
2010
Aux conventions comme Japan Expo ou Epitanime, l’association vendait des goodies, notamment des fanzines parfois faits en LaTeX4 :

La Brigade SOS est ainsi parvenue à récolter quelques milliers d’euros, lui permettant d’inviter l’illustratrice originale de Haruhi Suzumiya Noizi Ito en France, à Epitanime 2010 ! Et ça les gars, c’est bien joué.

Photo par Rin-kun, sur Wikipédia.
2011
En faisant un peu de veille, j’ai découvert que le festival Scotland Loves Animation projetterait à Édimbourg en octobre le film en avant-première européenne : La Disparition de Haruhi Suzumiya.
Du coup, la Brigade y est allée ! À l’époque, il existait pour des saisons comme celle-ci des billets Ryanair à 7 € aller, 12 € retour (la folie). Du coup, on mangeait des pancakes, on allait voir un film, on revenait à l’auberge manger des pancakes, on retournait voir un film, etc. pendant une semaine.
Et le film était à la hauteur de nos espérances. Un bijou d’animation de 2 h 42 et 53 secondes que je vous conseille vivement, même si vous n’avez pas vu la saison 2 en entier (la saison 1 + l’épisode Bamboo Leaf Rhapsody suffisent). Voici un extrait5 :
2013
Résigné à ce que les tomes restants de la série ne soient jamais adaptés, je me suis attaqué à la lecture des romans en anglais. Si vous avez vu la série, je vous conseille vivement la lecture de « Snow Mountain Syndrome », le dernier chapitre du tome 5.
D’ailleurs je viens de voir qu’il existe des fans tellement désespérés qu’ils l’ont… animé eux-mêmes :D
2016
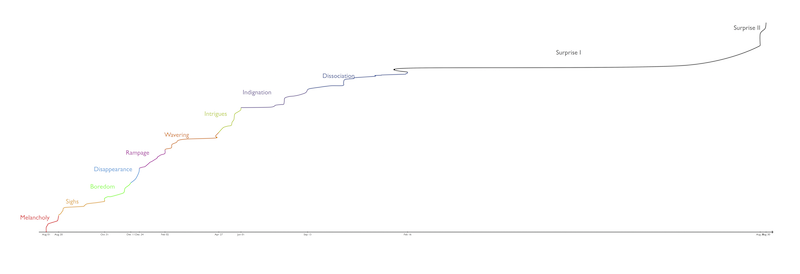
J’ai enfin fini les romans. Et oui, je suis suffisamment taré pour avoir enregistré ma progression de lecture sur un repo GitHub, pendant 3 ans6.
Au final, ceux qui font vraiment avancer l’intrigue sont les tomes 1, 4, 7 et 10.
Et voici un précieux conseil d’écriture de l’auteur dans les dernières pages, qui s’excuse d’avoir mis 4 ans entre le neuvième et le dixième tome :
Il semblerait qu’après être arrivé à saturation d’avoir ma capacité d’écrire poussée dans ses derniers retranchements, j’ai immédiatement eu l’idée pour La Disparition de Haruhi Suzumiya, et j’ai écrit les séries d’histoires alors même qu’elles me venaient à l’esprit. Ainsi, je me dis que ma pensée selon laquelle « Si tu crains de ne pas y arriver, écris juste tout » était plutôt bonne.
En somme, suivez cet algorithme
- Regardez la saison 1 de La Mélancolie de Haruhi Suzumiya
- Peut-être pas toute la saison 2, mais au moins « Bamboo Leaf Rhapsody »
- Délectez-vous du film La Disparition de Haruhi Suzumiya
- Lisez « Snow Mountain Syndrome », et les tomes congrus à 1 modulo 3.
Partition : Bouken Desho Desho?, opening de la saison 1.
-
Hélas récemment dissoute ! Mais nos cœurs en ont été grandis. ↩
-
Que l’on pouvait suivre en direct en France car l’épisode passait à 25 h au Japon, soit 18 h en France. ↩
-
Bon, ceux qui ont vu la saison 2 savent que les prophètes – tout prophètes fussent-ils – ne pouvaient pas imaginer que la saison 2 se déroulerait comme elle s’est déroulée. ↩
-
Si, si. ↩
-
Ah oui, j’ai oublié de dire que la BO du film était principalement composée de gymnopédies d’Erik Satie. ↩
-
Notez la longue coupure, qui correspond aux dernières années de thèse. ↩