Antoine était de passage à Tokyo. Un type de son labo a cru bon de me demander un service (ERREUR ! il jura qu’on ne l’y reprît plus).
Bref, j’ai commandé sur Amazon une lentille d’appareil photo (50000 ¥ le machin). Le truc était censé arriver 5 jours plus tard.
À la fin du séjour d’Antoine, toujours pas de nouvelles d’Amazon.
Finalement, deux semaines plus tard, je reçois un mail (en japonais) disant : « Lol on vient de recevoir l’objectif en fait, on vous l’envoie. » Objectif reçu.
Escale à l’aéroport Pudong de Shanghai (à minuit, sobre). Au moment d’entrer dans le 2e avion, je me rends compte qu’il me manque quelque chose et qu’il faut que je fasse demi-tour. Nous sommes à 15 minutes du décollage.
L’équipage m’accompagne. Sur le chemin, le stewart me demande :
On fait marche arrière, on repasse les portes d’embarquement. L’équipage nous dit de nous dépêcher. Je me rends compte que ma valise n’est pas aux portes, comme je le croyais. Je me dis que je l’ai sûrement laissée dans les toilettes, ou carrément au contrôle de sécurité, ou carrément dans le 1er avion.
L’équipage me fait signe que je ne peux pas aller trop loin, donc on remonte dans l’avion. Je suis décontenancé. Le stewart, sympa, me donne le numéro X des objets trouvés de l’aéroport.
Les Chinois
Arrivé à Paris, je tente le service de réclamation des bagages, en sachant pertinemment que la valise était un bagage à main, et donc que tout était bien de ma faute (même si le bagage a été volé). Mon interlocutrice le savait, mais elle a eu la sympathie d’essayer quand même.
Je téléphone en VoIP au numéro X des objets trouvés, décris ma situation en anglais. On me renvoie vers un numéro Y.
— For English press 2.
— *appuie sur 2*
— For baggage inquiry press 1.
— *appuie sur 1*
— *quelque chose en Chinois* puis ça raccroche.
Je réessaie plusieurs fois, même format. Du coup, j’essaie d’envoyer un mail. En anglais, et en Google-Translated chinois.
Soudain, l’illumination : je me rends compte que deux jours plus tard, je rentrerai par le même aéroport. Tout n’est donc pas perdu.
Une fois de retour à Shanghai donc, je me rends aux objets trouvés.
— Qu’est-ce qu’il y a dans votre valise ?
— Un Pikachu.
— Quoi d’autre ?
— Une caméra.
— Pas de caméra.
— ??? Vous n’avez rien ?
— Non.
Je me dis que j’ai peut-être raté l’entretien en disant « caméra » plutôt que « lentille », mais j’essayais de lui retranscrire ça pêle-mêle, aussi.
Je vais voir le guichet de la compagnie aérienne et leur dis que j’ai peut-être laissé une valise dans mon premier vol. Ils téléphonent, et me disent que non.
… De retour au Japon, je demande à ma fiancée de téléphoner au numéro X des objets trouvés. On la redirige vers le numéro Y qui lui raccroche au nez. Mais comme elle parle chinois ❤️, elle me donne deux informations supplémentaires :
— le numéro Y est celui de la compagnie ;
— le message en chinois disait : « Merci pour votre appel, bon voyage, au revoir ! » Sans intervention humaine, juste après avoir sélectionné le bon service en appuyant sur les touches du téléphone.
Ça semblait limpide : puisque j’avais oublié une valise (même après avoir bien dit « carry-on »), c’était trop facile pour eux de me rediriger vers le numéro de la compagnie aérienne.
Nous sommes Les Chinois
Lundi 16 décembre. À l’université de Kyoto, je demande à un pote thésard chinois de téléphoner aux objets trouvés pour moi. Je lui précise qu’il y a sûrement 5 % de chances que ça marche (puisque j’y suis allé moi-même, et que ma fiancée les a eus au téléphone) mais que je veux les tenter quand même.
Il appelle le numéro X, commence à décrire la situation. Puis il me demande :
— Est-ce un bagage à main ?
— Oui.
(On patiente cinq minutes.)
— Quelle est la couleur de la trousse de toilette ?
— Gris.
Puis il se met à griffonner des informations en chinois. Je me dis que c’est pas possible. Pour poser une question pareille, ils doivent avoir retrouvé ma valise. On n’est pas passés par la case « compagnie aérienne prison ». On gagne 50000 ¥.
— Il faut que tu ailles leur remettre ce numéro.
— ILS ONT RETROUVÉ MA VALISE ???
— Ah, oui. J’aurais dû commencer par ça.
Mon ami me précise qu’ils peuvent garder la valise 6 mois, que je peux la chercher moi-même ou envoyer quelqu’un, et qu’il faut que je leur donne son numéro de téléphone en guise d’identification. Je songe alors à mon cousin, qui s’y rendra dans quelques mois.
Jeudi 19 décembre. Un collègue chinois à Tokyo me demande : « Hey, pourquoi avais-tu besoin de moi l’autre jour ? » Je lui raconte toute l’histoire et lui précise : « Je voulais que tu appelles les objets trouvés de l’aéroport de Shanghai pour moi, mais t’inquiète ! je n’en ai plus besoin. »
Puis je continue :
— Au fait, demain c’est mon dernier jour de l’année, ce serait bien qu’on parle recherche quand même.
— Oui, déjeunons ensemble, parce que le soir je dîne avec des amis qui viennent de Shanghai. Attends. Ils viennent de SHANGHAI. Je vais les contacter tout de suite.
— Oh bon sang. S’ils y parviennent, it will be CHRISTMAS!!!
Je prépare à toute allure tous les papiers :
C’est la lettre originale. Vous noterez que j’ai pris soin de traduire les noms des peluches Pokémon en anglais et chinois.
copie de mon passeport
copie de ma carte d’embarquement (optionnel, mais mieux)
Vendredi 20 décembre. Le lendemain matin, les amis de mon collègue se rendent au service des objets trouvés avec tous les papiers. Problème, leur interlocuteur ne reconnaît pas le numéro de mon ami thésard à Kyoto. Du coup, ils téléphonent au numéro que je leur ai donné, et tombent sur une femme (??!). Je commence à perdre espoir, si près du but !
Puis finalement, par Messenger interposé, je réponds à toutes les questions de leur interlocuteur (où ai-je oublié ma valise et à quelle heure, pour prendre quel vol),
et……… ILS RÉCUPÈRENT MA VALISE !!
Le soir, ils me l’ont rendue au labo !
Conclusion
Le Père Noël existe !!! Et il est chinois !! Joyeux Noël !
J’ai voulu envoyer un colis en Chine1, le lot du Mangaki Data Challenge. Pour compliquer la chose, il fallait que j’envoie : un livre, un CD et une lettre.
On m’avait conseillé de l’envoyer depuis la Chine plutôt que depuis le Japon, pour que ce soit moins cher.
Préambule
À un certain moment du voyage, je demande à George :
« Tiens mais c’est marrant, d’un côté tu as Jinmen 金门 (portail d’or),
et de l’autre Xiamen 厦门. Mais du coup ça veut dire quoi le Xia de Xiamen ?
— Ça ne veut rien dire, c’est un nom propre.
— Mais pourtant ça ressemble à 夏 (été) ?
— Oui mais le caractère est complètement différent.
— Bah y a juste 厂 en plus quoi.
— Oui mais c’est complètement différent. 厦 ça veut dire building. Mais c’est un nom propre.
— D’accord. »
Essai 1, à l’hôtel
L’adresse en poche, je demande à mon hôtel de l’envoyer.
L’hôtellière parvient avec peine (et Baidu) à déchiffrer l’adresse écrite en caractères latins. Puis elle me demande : « Au fait, vous avez le numéro du destinataire ?
— Euh non.
— Ah ben c’est pas possible alors. »
Échec. Je demande au gagnant son numéro de téléphone.
(Elle a jeté un œil au colis et a dit : “あ、日本語が喋れる!” (« Ah, vous parlez japonais ! ») bref, elle aurait préféré communiquer en japonais plutôt qu’en anglais.)
Essai 2, près de l’aéroport
« Un CD ? Non, vous n’allez jamais pouvoir envoyer ça.
— Pourquoi ?
— Est-ce que c’est un original ?
— Oui.
— Si ce n’est pas un original, il sera effacé. D’accord ?
— Euh ben OK. »
(Je ne sais pas comment ils font pour savoir si c’est un original ou pas.)
« Envoi en express ou normal ?
— Normal.
— Si normal, vous ne pourrez pas envoyer la lettre dans le colis, il faudra l’envoyer séparément.
— Ah ben va pour Express alors. »
Elle me remet un formulaire EMS entièrement en chinois. George m’aide à savoir quoi remplir où. Après le lui avoir rendu, elle me dit :
« Non. Il faut tout remplir avec des caractères chinois. »
Échec. Je n’ai pas son adresse en chinois. Tant pis, j’enverrai depuis le Japon.
BONUS GRATUIT : Essai 3, à l’aéroport
Une fois le bagage déposé, j’ai quand même envie de retenter. Je cherche une poste dans l’aéroport. En parallèle je cherche sur Baidu une adresse approchante. Une fois trouvée (!), je ne sais pas quelle est la sous-chaîne2 de l’adresse qui m’intéresse, et qu’est-ce que je dois jeter.
Il y a effectivement un espace « Inquiry », avec deux femmes ne parlant pas anglais. Je leur montre le formulaire EMS. Elles appellent une amie. L’une d’elles m’apporte du thé. Ah non, c’est pour elle. (Foutu résident japonais trop habitué à être traité comme un roi.)
On patiente. Je lui montre la carte d’embarquement qui précise que j’embarque 30 minutes plus tard. Elle panique et dit à son amie nouvellement arrivée de se presser. Serious business incoming.
Challenge 1
Je lui montre le morceau d’adresse que j’ai trouvé sur Baidu, elle commence à la recopier… sauf qu’à un moment je l’interromps :
“之是大厦25” (« Là il faut écrire Building 25 »)
Là elle répond par (j’imagine) : « Attends pourquoi tu m’embêtes je recopie ton adresse alors que tu parles même pas chinois. »
Mais elle écrit “大厦25.”
Challenge 2
Je n’ai pas le nom du destinataire en caractères chinois.
Elle râle un peu, mais avec sa copine elles se convainquent que le numéro de téléphone suffira.
Challenge 3
Elle me demande mon adresse.
Je commence à écrire mon adresse au Japon en kanji.
“No! No! No! China to China!”
Argh. Si près du but.
Je fouille dans mon sac, je trouve miraculeusement le calepin de l’hôtel, avec son adresse !
“20 yuans.” Je paye et file prendre mon avion. “谢谢🙏” (« Merci ! »)
Moralité
Posez-vous plein de questions sur les caractères à la con.
Gardez les morceaux de papier des hôtels. Ça peut sauver des vies.
Et… 20 yuans (2,50 €) pour un envoi en Express d’un livre, un CD et une lettre ??!!
WOW, ça vaut le coup !
Thanks @jjvie for the present and the handwritten letter! (Fireworks is not yet on screen in China, but received OST first🙃) pic.twitter.com/ETvLq5jg0U
Il y a 3 ans jour pour jour, le Trio ELM faisait son premier concert, à l’ENS Cachan, à l’occasion des rencontres culturelles interENS :
En voici la playlist complète ainsi que le programme :
À l’époque, on avait une certaine culture du teasing, donc on avait décidé de révéler les musiques du concert petit à petit, et on avait même proposé aux gens de suggérer des musiques via un input.
(Forcément, on s’est retrouvé avec les trolls classiques : l’opening de Naruto en allemand, les Chœurs de l’Armée rouge, 4’33” de John Cage, etc.)
Et en fait, on transcrivait nos partitions nous-mêmes ! On les a interprétées à Japan Expo en 2015, Japan Expo Sud en 2016, et plusieurs années à Epitanime et d’autres conventions.
C’est l’occasion pour moi de revenir sur 12 ans de transcription de partitions de musique d’anime.
Quel langage choisir pour mettre en page de la musique ?
Prenons une musique de piano.
Ces notes au piano constituaient la musique de fond de la page Web de .hack//G.U., un jeu qui était très attendu en 2005. Il fallait transcrire cette musique.
MusiXTeX, un langage pour écrire des partitions en TeX
Je l’ai transcrite en MusiXTeX en 2005, mais le code donnait ça. (Ma première partition par ordinateur.)
Assez indigeste. C’est parce qu’on peut régler tout, jusqu’à l’angle d’inclinaison des ligatures.
PMX, un langage plus simple qui produit du MusiXTeX
Plus tard, j’ai découvert qu’il existait des méthodes plus simples !! (Sans déconner.)
Don Simons a codé un préprocesseur pour le MusiXTeX. Le langage s’appelle PMX et est plus lisible :
1 1 3 4 3 4 0 -4
0 5 16 0.085
Piano
t
./
It60ipi
Tt
.hack//G.U. - Desktop
Tc
Chikayo Fukuda\\Transcribed by Jill-J\^enn Vie
f83 c+ f g af c | ef c a f e d | c2 r4 /
Les premières lignes constituent le préambule, pour indiquer l’armure, la mesure, les instruments, et le tempo du fichier MIDI. Le cœur de la partition est la dernière ligne :
f83 c+ f g af c | ef c a f e d | c2 r4 /
Ce qui donne : fa do fa sol la♭ do | mi♭ do la fa mi ré | do
(Bon j’ai mis des bémols alors qu’ils sont déjà à l’armure mais comme ça vous voyez comment ça marche.)
Par défaut la note suivante est la plus proche, si on souhaite changer d’octave on a + ou -.
8 (8th) indique qu’il s’agit de croches (4 : noires, 2 : blanches, etc.).
f (flat) indique un bémol, s (sharp) un dièse.
r (rest) est un soupir.
Ce qui est appréciable, c’est que PMX peut créer un fichier MIDI en plus de la partition (.tex), ce qui aide au debug. Sur mon site vous avez une centaine de partitions créées à partir de ce langage.
Je mettrai les sources en ligne, mais il y en a qui ont sombré avec mes anciens ordinateurs 😢.
Il existe aussi LilyPond, mais je trouve ce langage plus compliqué, même s’il faut reconnaître que la communauté est très vivante, et que cela permet un rendu plus net.
VexFlow
Depuis lors, un framework open source a été développé par un fou furieux en JavaScript, qui génère des commandes canvas ou du code SVG, avec lecture audio dans le navigateur, s’il vous plaît ! Ça s’appelle VexFlow et c’est sur GitHub.
D’autres personnes appréciant le côté feedback immédiat ont codé une surcouche propriétaire du framework open source VexFlow. Leur langage est extrêmement simple (mais du coup, limité) :
Ici des fa d’octaves croissants seront représentés par :
FFF FF F f f' f'' f'''
Tandis que - et + permettent de mettre des bémols et dièses.
Le mouvement OpenScore
Vous devez connaître IMSLP (International Music Score Library Project), c’est la plus grande base de données de partitions dans le domaine public. Ils se sont associés en janvier 2017 avec le logiciel open source MuseScore lors du dernier FOSDEM (Free and Open Source Software Developers’ European Meeting) pour former OpenScore, une initiative visant à ouvrir le code source des musiques pour faciliter les reprises, arrangements, mais aussi l’indexation et l’extraction de données pour la recherche. En savoir plus sur le site du FOSDEM ou de MuseScore.
La question est de savoir quel standard va gagner (MusicXML ? ou le format MSCZ de MuseScore ?).
Connaissez-vous d’autres initiatives prometteuses ? Vous pouvez en faire part dans les commentaires ci-dessous.
Quelques anecdotes à propos des partitions transcrites
Final Fantasy - Swing de Chocobo
Pour moi, le meilleur arrangement philharmonique du thème de Chocobo dans Final Fantasy, c’est Swing de Chocobo issu de Final Fantasy X.
Pour le concert des prépas du lycée Thiers en 2008, on souhaitait à tout prix en faire une interprétation à six instruments + piano. MAIS impossible de mettre la main sur un trompettiste.
Je ne sais plus comment j’ai su que le documentaliste du CDI savait faire de la trompette. Du coup on est allés le voir :
— BONJOUR, paraît que vous savez faire de la TROMPETTE ?
— Hein ? Oui mais je…
— S’IL VOUS PLAÎT c’est important.
Du coup c’était parfait de faire du PMX, parce que j’ai pu pondre toutes les versions pour tout le monde à coups de copier-coller :
Vous pouvez écouter notre interprétation ci-dessous (ça commence à 1:33) et voir toutes les partitions là. C’était une super expérience.
Cosmo Warrior Zero - The Book of Life
Connaissez-vous le merveilleux ending The Book of Life de la série Cosmo Warrior Zero ? Non. Très bien.
Un jour, pour une raison que j’ignore, je suis tombé sur une interprétation live de ce morceau par un quatuor de 3 chanteuses mexicaines et 1 piano : el Cuarteto Nausicaä. Ça se déroulait à l’équivalent mexicain de Japan Expo.
Comme je me souvenais que le refrain était difficile à transcrire au piano dans la musique originale, je me suis demandé : « Tiens, comment elles ont fait, elles ? » puis, au moment du refrain : « Attends… elles ont fait comme moi… SE POURRAIT-CE QUE ? » J’ai écrit à la pianiste, et elle m’a dit : « Yes, you’re right, it’s yours! » Wow.
Ghost in the Shell - I Do
Cette petite pépite nous vient de la compositrice de génie Yoko Kanno, qui compose 50 % du programme du Trio ELM (dont ELM de la série géniale Cowboy Bebop), dont le trio tire son nom).
À l’été 2016, avec Ryan Lahfa, on a remporté un voyage au Japon pour notre projet de système de recommandation Mangaki. À l’aéroport, comme il y a des pianos, on en a profité pour interpréter de la musique d’anime. Alors que Ryan était en train de jouer Sadness and Sorrow de Naruto, un Russe nous a interpellé : « Hey guys, could you please play this? » et il nous montre ceci :
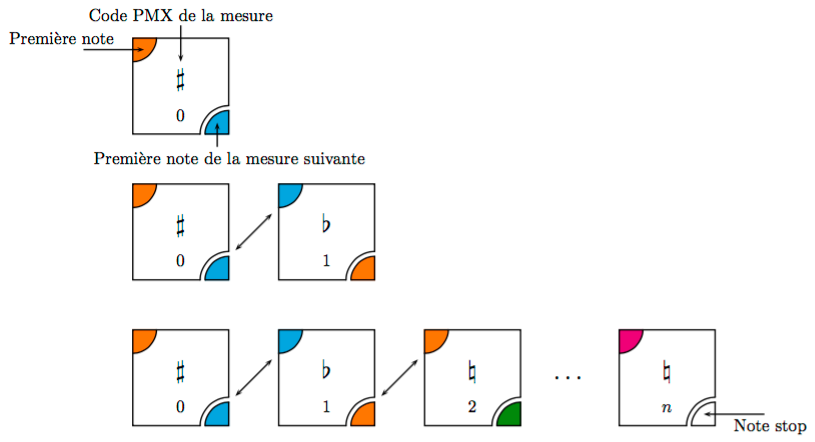
Avoir tout ce corpus de partitions PMX, c’était pratique quand j’ai voulu faire mon TIPE de génération procédurale de musique par chaînes de Markov. Le programme prenait en entrée des partitions au format PMX et générait une partition PMX inédite, mesure par mesure.
Quand j’ai voulu faire écouter ce que l’algorithme faisait au jury des ENS, ils m’ont dit :
— On aimerait bien écouter mais pour ça il faudrait que votre portable reste dans la salle après l’oral.
— Ah ben non alors.
Voilà, et pour revenir à l’anniversaire de Trio ELM, sa vidéo la plus vue est : Sis Puella Magica, de Puella Magi Madoka Magica. Et si vous voulez écouter d’autres vidéos, c’est sur le site de trioelm.com ! Joyeux anniversaire, Sedeto et Lily !