Ou pourquoi vous auriez dû être au Collège de France jeudi 4/2 au soir. Par David Lambert et JJ Vie.
Update 13/02. Rassurez-vous, la vidéo est déjà disponible sur le site du Collège de France !
Update 18/04. Google a fait une super page pour introduire à leur outil de deep learning, TensorFlow ! http://playground.tensorflow.org
Préambule
NLDR/TLDR. Le deep learning est une méthode d’apprentissage automatique. Vous en avez peut-être déjà entendu parler sous le nom de réseaux de neurones artificiels. En fait, les modèles existent depuis les années 80, mais ont réellement explosé en 2012, voir plus bas. Yann LeCun est un des pionniers de ce domaine, notamment pour avoir créé les réseaux convolutionnels (ConvNets), décrits plus bas.
S’inspirer du cerveau est-il légitime ?
En extrapolant à partir de l’état actuel de l’électronique, on peut supposer que les processeurs seront aussi performants qu’un cerveau humain en 2045 (si la loi de Moore ne se heurte pas entre-temps aux limites de la miniaturisation).
Mais en recherche, la vraie question n’est pas simplement d’égaler sa puissance de calcul, mais de comprendre comment marche le cerveau. Il s’agit de saisir l’essence de son fonctionnement, plutôt que de chercher à le reproduire dans ses moindres détails. Les avions n’ont pas de plumes, et n’en ont pas besoin ; l’avion III de Clément Ader, trop proche physiquement de la chauve-souris, n’était pas une franche réussite.

Trois types d’apprentissage automatique
Apprentissage par renforcement

Méthode façon « la carotte et le bâton » ; on pénalise l’algorithme s’il aboutit à une mauvaise solution, on le récompense s’il fait les bons choix.
C’est un processus lent, mais dans les jeux vidéo, c’est relativement facile, car on peut simuler des parties très vite (NDLR, cf. les travaux de Deep Mind sur les jeux Atari en février 2015 ou bien AlphaGo bat un champion européen le 27 janvier 2016, publié dans Nature).
Apprentissage supervisé
On imagine ici qu’on a accès à des étiquettes sur les données qu’on considère (« ceci est une voiture », « ceci est une blonde aux yeux bleus »).
La classification d’objets est donc un bon exemple. Dans tout ce qui suit, on va parler d’apprentissage supervisé, domaine de la recherche en perception artificielle, sous-domaine de la recherche en intelligence artificielle.

Apprentissage non supervisé
NDLR. Là, on suppose qu’on n’a pas accès à des étiquettes. Ainsi, les approches usuelles consistent à regrouper les données en clusters, ou tenter de visualiser les données selon certains angles (analyse en composantes principales). Par exemple, en recommandation de films, on essaie de rapprocher des utilisateurs d’autres en fonction de ce qu’ils ont aimé, pour essayer de visualiser certains profils-types.
Pour en savoir plus, l’excellent tutoriel scikit-learn (en anglais) : An introduction to machine learning with scikit-learn.
Le perceptron (1957)
Principe : on cherche à distinguer deux catégories d’images, par exemple distinguer les A des B, en les soumettant à la machine. Chaque image est composée de pixels noirs ou blancs (1 ou 0) et on souhaite qu’à la sortie on ait :
- une valeur positive si l’image est un A ;
- une valeur négative si l’image est un B.
En fait, chaque pixel participe à la valeur de sortie de la machine selon un certain poids, et la somme pondérée de toutes les entrées donne une valeur globale qui indique si la machine « pense » que l’image est un A ou un B. Si la machine s’est trompée, les poids sont corrigés (on pénalise les poids des pixels qui l’ont induite en erreur) ; la machine apprend ainsi par tatônnements (trial and error), on appelle cela la phase d’entraînement. On itère le processus jusqu’à ce que la fonction d’erreur du système soit convenable.
Les poids relatifs des sorties de chaque cellule sont modifiés comme seraient modifiées les connexions entre neurones dans le cerveau, en fonction de la conformité du résultat.
Un perceptron efficace possèdera la propriété de généralisation : identifier correctement une image qu’il n’a alors jamais vue !

NDLR. Si la reconnaissance de chiffres vous intéresse, voici un code Python tiré d’un tutoriel de scikit-learn par Gaël Varoquaux (qui utilise une SVM plutôt qu’un perceptron).
Deep learning
L’idée du deep learning, c’est de brancher des perceptrons entre eux, regroupés en couches, de façon hiérarchique. Et d’entraîner toutes les couches en même temps.
Chaque couche est responsable d’un certain niveau d’abstraction :
- un module de niveau 1 détecte l’état d’un pixel (noir ou blanc, présence ou absence) ;
- un module de niveau 2 s’occupe des conjonctions de pixel et détecte ainsi les contours ;
- un module de niveau 3 détecte les motifs dans les contours, et ainsi de suite.
Tout ça, ça marche parce que le monde est compositionnel – je ne sais pas si c’est un mot français mais je l’utilise. Un ami dit plutôt, de manière amusante : « Soit le monde est compositionnel, soit Dieu existe. »
Cette hiérarchie des caractéristiques (pixel, contour, motif de contours) on la retrouve dans d’autres objets d’étude des réseaux de neurones, comme les langues par exemple (caractère → phonème → syllabe → mot → phrase → livre).
Réseaux convolutionnels
Je les appelle ConvNets pour éviter qu’on les appelle CNN (convolutional neural networks)…
Lecture automatique de chèques (1996)
Yann LeCun a développé un modèle sur le même principe, qui permet entre autres de :
- reconnaître un chiffre à n’importe quel endroit de l’image (invariant par translation, NDLR) ;
- faire le tri entre motif et fond de l’image.
Première application : une machine de lecture automatique de chèques (Bell Labs), déployée aux États-Unis en 1996. 20 % de tous les chèques américains sont passés par cette machine, qui rejetait 50 % du tas mais ne faisait qu’1 % d’erreur, ce qui est convenable en pratique.
Le dataset ImageNet (2012)

Mais dans la communauté scientifique, personne ne s’est intéressé aux réseaux convolutionnels avant 2012, lorsque le dataset ImageNet (1,2 millions d’images, classées dans un millier de catégories) est sorti. Là, en 18 mois, il y a eu un revirement mondial, qui a eu pour conséquence la « redécouverte » de certains concepts par des nouveaux venus, ce qui brouille la visibilité des travaux des équipes précédentes :
Détection de piétons ou d’obstacles (scene parsing / labeling)

Les ConvNets ont été appliqués à l’interprétation d’image par étiquetage de chaque pixel en fonction de la partie de l’image à laquelle il appartient (façade, chaussée, passant, voiture). Chaque sortie tient compte du contexte du pixel d’entrée (NDLR, par analogie avec un puzzle, la machine a la possibilité de distinguer le bleu du ciel et le bleu du reflet du ciel dans le lac si elle détecte une rive).
Cela a fait progresser les travaux en vision robotique à longue distance, cf. cette vidéo (DARPA LAGR/NYU/NetSCALE, 2005-2008), voir à 4:08 :
La première fois que mon étudiant s’est jeté devant le robot, j’ai failli avoir une attaque. Il faut vraiment avoir confiance en son code pour se jeter devant un robot de 120 kilos qui peut vous casser la jambe s’il ne s’arrête pas à temps. D’ailleurs maintenant quand des étudiants veulent travailler avec moi, d’abord je leur fais écrire un peu de code du robot, je les fais sauter devant ; s’ils survivent, je les prends.
Reconnaissance vocale
Avant, les ConvNets étaient principalement utilisés pour la reconnaissance d’images, mais ça s’est propagé à d’autres domaines de l’intelligence artificielle.
Le service de reconnaissance vocale OK Google utilise des ConvNets. Des travaux récents sur les ConvNets polyglottes, entraînés à la reconnaissance vocale dans plusieurs langues, montrent que ceux-ci sont ensuite plus performants dans chacune des langues individuelles (NDLR, ça fait penser au fait que certains conseillent d’apprendre l’espéranto pour apprendre plus vite les autres langages ; il y a des études, mais je ne sais plus où elles sont).
Légendes automatiques
À partir d’une photo, un algorithme peut en décrire le contenu.

On développe [ces systèmes] chez Facebook, en particulier pour aider les malvoyants à avoir une idée de ce qui se passe dans leur flux d’informations.
À noter que la fonctionnalité de reconnaissance des visages de Facebook est désactivée en Europe.
Modèles génératifs
On peut aussi prendre le réseau à l’envers et de demander à afficher quelque chose d’inédit à partir de nombres aléatoires. Par exemple :
- certains génèrent des phrases ;
- d’autres des photos de chambres ;
- d’autres des personnages de mangas !

Jetez un œil au repo GitHub associé : Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.
Memory Networks
La plupart des modèles ont un peu une mémoire de poisson rouge (NDLR). Ils fonctionneraient mieux s’ils avaient l’équivalent de l’hippocampe pour le cerveau (NDLR, ou de la RAM pour les ordis), une mémoire partagée. C’est ainsi qu’on a créé le paradigme des Memory Networks.
Ainsi, on pourrait attendre d’un algorithme qu’il soit capable de répondre à la question : « Brian est dans la cuisine. Brian prend du lait. Brian va dans la salle de bains. Où est le lait ? »
(NDLR : je vous laisse imaginer ce qu’un tel outil est capable de faire si on lui donne accès aux données de Facebook.)
Traitement des langages naturels (par ex., word2vec)
Effet secondaire de l’entraînement du système : celui-ci fait spontanément émerger des structures à partir des données qu’il a ingurgitées.
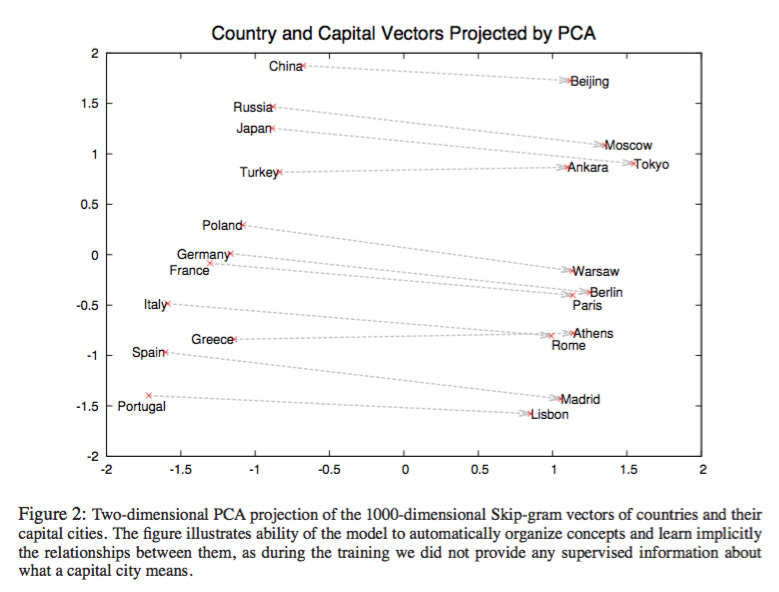
Du coup, on peut demander à la machine : « Qu’est-ce qui est à l’Allemagne ce que Paris est à la France ? » et elle est capable de répondre « Berlin ».
Autant faire la même chose avec des photos de visages : on peut demander à l’ordinateur de générer une photo de femme avec des lunettes en effectuant l’opération : « homme avec lunettes – homme sans lunettes + femme sans lunettes ».

Conclusion
Que ne sait-on pas faire ?
Les quatre chaînons manquants de l’intelligence artificielle :
- une compréhension théorique de l’apprentissage profond : ça marche, mais on ne sait pas pourquoi ça marche aussi bien ;
- une intégration de ces méthodes d’analyse des représentations (apprentissage profond) aux quatre autres composantes de l’intelligence, qui seraient le raisonnement, l’attention, la planification et la mémoire ;
- une théorie unifiée de l’apprentissage : un système qui déploierait à la fois des capacités d’apprentissage par renforcement, d’apprentissage supervisé et d’apprentissage non supervisé ;
- une modélisation efficace de l’apprentissage non supervisé.
Métaphore du gâteau
Actuellement, sur les trois formes d’apprentissage chez les humains :
- Apprentissage par renforcement : c’est la cerise, c’est facile, on sait faire.
- Apprentissage supervisé : le glaçage (NDLR, pour lequel le deep learning s’est révélé très efficace).
- Apprentissage non supervisé : 90 % restants du gâteau, qu’on ne sait pas faire de façon satisfaisante.

L’apprentissage non supervisé pourrait être effectué par un algorithme prédictif dont les résultats seraient pondérés en fonction de la conformité des prévisions avec ce qui s’est produit. C’est l’apprentissage via un modèle prédictif du monde qui nous enseigne le bon sens : quand on lit la phrase « Gérard prend son sac et quitte la pièce », on en déduit que Gérard prend son sac avec sa main, qu’il quitte la pièce par la porte et pas par la fenêtre, ni en volant ni en se téléportant, etc. Pourquoi ? Parce qu’on a appris tout cela au préalable, en observant le monde.
Certains font de la prédiction de frame de film, mais cela ne fonctionne pas très bien, ne serait-ce que parce qu’on ne connaît pas l’état du monde, seulement ce qui est observé à l’écran (NDLR, un T-Rex qui apparaîtrait soudainement dans Jurassic Park).
Et la domination des machines sur l’homme, alors ?
La différence entre l’intelligence humaine et l’intelligence machine est que nous sommes soumis à un ensemble d’instincts, dont la programmation est le résultat du processus d’évolution dont nous sommes le fruit, et que ce sont ces instincts (territorialité, jalousie, …) qui nous font faire n’importe quoi.
Il n’y a aucune raison de construire ces pulsions de base dans les robots : on peut construire des robots qui ne sont pas dangereux.
(NDLR, les algorithmes reflètent déjà aujourd’hui les biais de leurs concepteurs.)
Quelques liens
- Captation (audio pour l’instant) de la leçon inaugurale de Yann LeCun sur le site du Collège de France
- Podcast du passage de Yann LeCun et Gérard Berry sur France Culture
- l’excellent tutoriel Python : An introduction to machine learning with scikit-learn.
- l’excellent tutoriel Deep Learning with Torch in 60 minutes, Torch étant le module open source de Deep Learning développé par des ingénieur de Facebook, Twitter et Google DeepMind
- également de nombreuses ressources sur deeplearning.net